In cybersecurity, quickly finding and reasoning over Common Vulnerabilities and Exposures (CVE) still matters. This project is a hybrid vulnerability search and analysis pipeline: it bridges keyword search and semantic retrieval (Sentence-BERT + FAISS), then layers a locally hosted DeepSeek-class LLM for structured technical analysis, plus NVD enrichment and a validation / self-refinement loop when model output is thin or malformed.
It is meant for research, labs, and threat-intelligence-style workflows, not as a turnkey production appliance without your own review, caching, and governance.
Acknowledgements
Thank you to the engineers whose feedback and ideas shaped this architecture:
FAISS: fast similarity search over normalized vectors (IndexFlatIP in the reference script).
DeepSeek R1 / Qwen family (example: 32B-class): served locally behind an HTTP API compatible with chat-completions style calls.
aiohttp and requests: async batching to NVD and synchronous LLM calls, depending on the code path.
JSON and regex: structuring data, stripping model “thinking” blocks, and validating section headers in LLM replies.
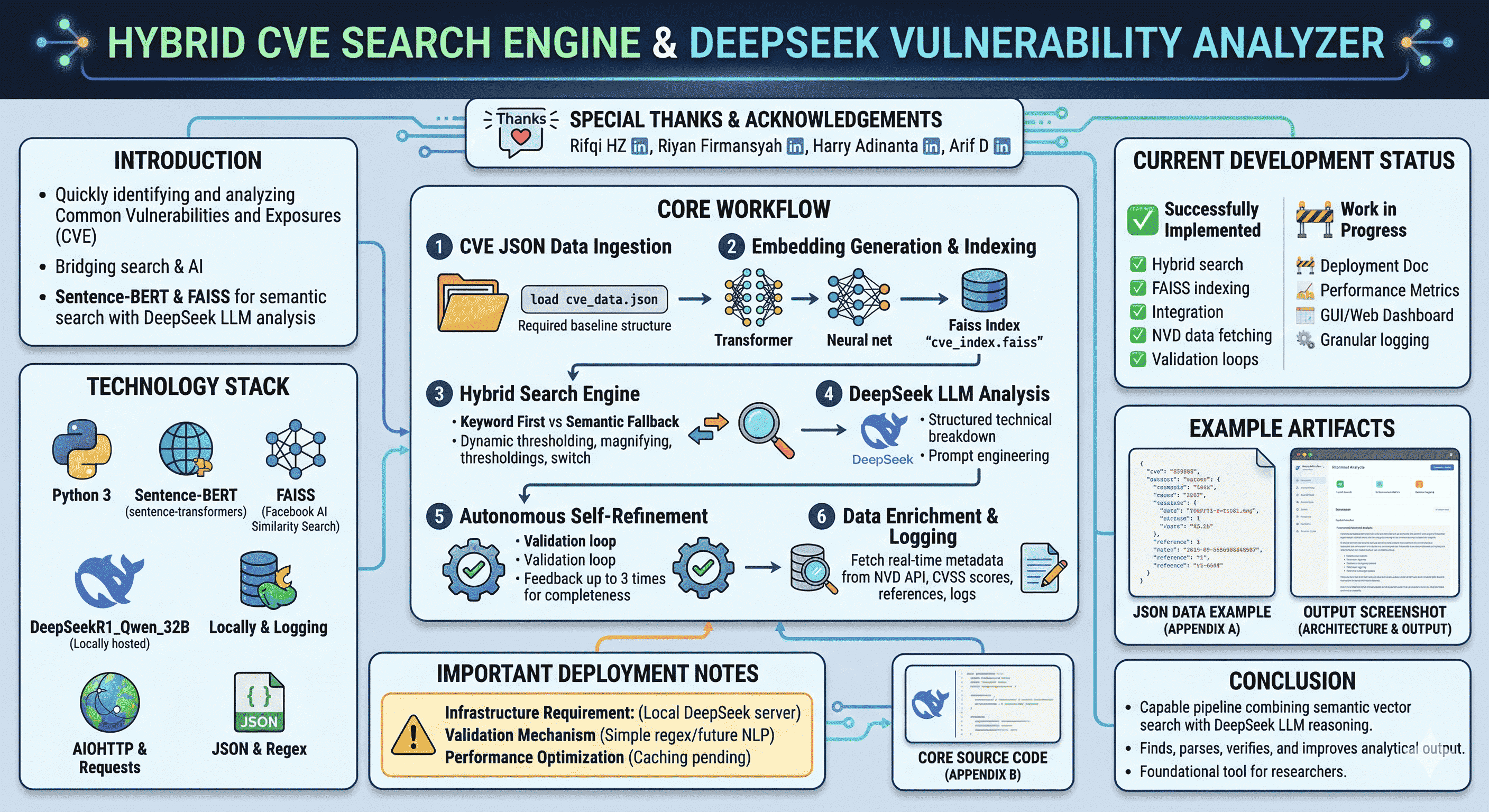
Core workflow
1. CVE JSON ingestion: load vulnerability records from cve_data.json. Each entry should include at least an id and an output field (description text used for search).
2. Embedding generation and indexing: encode every output with Sentence-BERT, L2-normalize embeddings, and add them to a FAISS index (saved as cve_index.faiss in the sample).
3. Hybrid search engine
Keyword first: scan descriptions for query terms, score with embedding cosine similarity when keywords hit.
Semantic fallback: if keyword results are weak, query FAISS with the query embedding.
Dynamic thresholding:adjust_threshold(query) tweaks similarity cutoffs from query length (short vs long queries).
4. DeepSeek LLM analysis: after retrieval, build a structured prompt (CVE id, advisory text, sections for type, severity, exploitability, components, mitigation). POST to your local model endpoint.
5. Autonomous self-refinement: if the reply fails validation (missing sections, too short), generate feedback, append previous response, and re-prompt, up to a small retry budget (e.g. three attempts).
6. Data enrichment and logging: fetch live metadata from the NVD JSON API (CVSS where available, references, timestamps). Print or log consolidated results.
tip
Replace BASE_URL, MODEL_NAME, and file paths with your server layout. Never commit API keys or internal hostnames you cannot share.
Current development status
Shipped in the reference prototype
Hybrid search (keyword path + FAISS fallback).
FAISS build, search, and index save/load pattern.
Local LLM HTTP integration.
NVD fetch and parse helpers (CVSS v4 / v3.1 / v2 fields as available).
Response validation and refinement loop scaffolding.
Still pending
Hardened deployment docs (Docker Compose, GPU notes, health checks).
Formal retrieval evaluation (precision/recall or nDCG on a labeled query set).
Web UI or dashboard instead of CLI-only.
Caching (embeddings, NVD responses, LLM outputs) for high-volume use.
Richer logging around each refinement attempt.
Important deployment notes
Infrastructure: you need the DeepSeek (or compatible) model running and reachable at the configured base URL; match tokenizer and context limits to your hardware.
Validation: current checks are mostly regex / structure. Stronger pipelines might add scoring, judge models, or human review for high-risk outputs.
Performance: without caching, repeated queries and large prompts can be slow or expensive, so plan batch sizes and concurrency limits.
NVD: follow NVD API terms and rate limits; add backoff on errors.
warning
Use this tooling only where you are authorized to query vulnerability data and run analysis. Combining CVE text with LLM output does not replace policy, legal review, or patch management.
Conclusion
The pipeline demonstrates how vector search and LLM reasoning can be chained for CVE-centric workflows: find candidates, enrich from NVD, then produce consistent write-ups, while iterating when the model drifts.
info
To run it yourself: start your local inference server, place a valid cve_data.json next to the script, install sentence-transformers, faiss-cpu (or faiss-gpu), aiohttp, and requests, then review the appendix code paths (especially async NVD batching and refinement) before trusting output in production.
Appendix A: Example cve_data.json
[
{
"id": "CVE-2025-21697",
"output": "The Linux kernel is vulnerable due to improper handling of job pointers. Specifically, after a job completes, the job pointer must be explicitly set to NULL to prevent warnings and potential crashes when unloading the driver. This vulnerability can lead to unintended behavior or memory corruption. The issue arises in the kernel's handling of job management, where a stale pointer may cause dereferencing of invalid memory. This issue affects kernel versions prior to the fix in the latest release, which addresses the pointer management. System administrators are advised to update their kernels to the latest stable version to mitigate potential risks of exploitation."
},
{
"id": "CVE-2025-0652",
"output": "A critical vulnerability exists in GitLab EE/CE versions 16.9 before 17.7.7, 17.8 before 17.8.5, and 17.9 before 17.9.2. Unauthorized users can exploit this vulnerability to gain access to confidential information. The issue arises due to improper access controls that fail to sufficiently restrict certain sensitive data, allowing unauthorized users to view or manipulate it. This can result in data leakage or unauthorized access to sensitive project information. GitLab has released fixes for affected versions, and users are strongly recommended to upgrade to the latest patched versions to prevent exploitation of this vulnerability."
}
]
Appendix B: Reference source (Python)
Below is the research / prototype script as used in development. Thread cve_info consistently through build_prompt in refinement paths, tighten SSL usage for NVD calls in production, and add tests before relying on it for anything critical.
import json
import aiohttp
from aiohttp import ClientSession, TCPConnector
import asyncio
import requests
import logging
import numpy as np
from sentence_transformers import SentenceTransformer
import faiss
import re
# logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
def load_cve_data(file_path):
try:
with open(file_path, 'r') as f:
return json.load(f)
except FileNotFoundError:
logging.error(f"File {file_path} not found!")
return []
except json.JSONDecodeError:
logging.error(f"File {file_path} is not a valid JSON!")
return []
class CVEModel:
def __init__(self, model_name='all-MiniLM-L6-v2'):
self.model = SentenceTransformer(model_name)
def encode_texts(self, texts):
embeddings = self.model.encode(texts)
return embeddings / np.linalg.norm(embeddings, axis=1, keepdims=True)
class FaissIndex:
def __init__(self, embeddings):
self.d = embeddings.shape[1]
self.index = faiss.IndexFlatIP(self.d)
self.index.add(embeddings)
def search(self, query_embedding, k=1):
distances, indices = self.index.search(query_embedding, k)
return distances, indices
def save(self, filename):
faiss.write_index(self.index, filename)
def adjust_threshold(query):
words = query.split()
filtered_words = [word for word in words if len(word) > 3]
num_words = len(filtered_words)
if num_words > 2:
return 0.5
elif num_words < 2:
return 0.1
elif num_words == 2:
return 0.3
return 0.7
class CVESearch:
def __init__(self, data, model, faiss_index):
self.data = data
self.model = model
self.faiss_index = faiss_index
def search_by_keywords(self, query, threshold=0.7):
query_lower = query.lower()
matching_entries = []
for entry in self.data:
matching_words = [word for word in query_lower.split() if word in entry['output'].lower()]
if matching_words:
output_embedding = self.model.encode_texts([entry['output']])
query_embedding = self.model.encode_texts([query])
similarity = np.dot(query_embedding, output_embedding.T)[0][0]
if similarity >= threshold:
matching_entries.append({
'ID': entry['id'],
'Distance': similarity,
'Output': entry['output']
})
return matching_entries
def search_query(self, query, k=1, threshold=0.7):
threshold = adjust_threshold(query)
keyword_results = self.search_by_keywords(query, threshold)
if keyword_results:
return keyword_results
query_embedding = self.model.encode_texts([query])
distances, indices = self.faiss_index.search(query_embedding, k)
results = []
for i in range(len(indices[0])):
idx = indices[0][i]
if distances[0][i] >= threshold:
result = {
'ID': self.data[idx]['id'],
'Distance': distances[0][i],
'Output': self.data[idx]['output']
}
results.append(result)
return results
BASE_URL = "{{URL}}"
MODEL_NAME = "{{DeepSeekModel}}"
HEADERS = {"Content-Type": "application/json"}
def chat_with_model(prompt):
payload = {
"model": MODEL_NAME,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 5000
}
response = requests.post(f"{BASE_URL}/chat/completions", json=payload, headers=HEADERS)
if response.status_code == 200:
return response.json()
else:
return {"error": f"Request failed with status code {response.status_code}"}
data = load_cve_data("cve_data.json")
cve_model = CVEModel()
output_texts = [entry['output'] for entry in data]
output_embeddings = cve_model.encode_texts(output_texts)
faiss_index = FaissIndex(output_embeddings)
faiss_index.save("cve_index.faiss")
cve_search = CVESearch(data, cve_model, faiss_index)
query = "server-side request forgery"
results = cve_search.search_query(query, k=5, threshold=0.5)
def clean_deepseek_response(response):
return re.sub(r"<redacted_thinking>.*?</redacted_thinking>", "", response, flags=re.DOTALL).strip()
async def fetch_cve_data(session, url):
connector = TCPConnector(ssl=False)
async with ClientSession(connector=connector) as session:
async with session.get(url) as response:
if response.status == 200:
return await response.json()
logging.error(f"Failed to fetch data from {url}")
return None
def parse_cve_data(response):
cve_item = response.get("vulnerabilities", [])[0].get("cve", {})
return {
"id": cve_item.get("id", "N/A"),
"published": cve_item.get("published", "N/A"),
"last_modified": cve_item.get("lastModified", "N/A"),
"description": next((d.get("value") for d in cve_item.get("descriptions", []) if d.get("lang") == "en"), "No description available"),
"cvss_v40": next((m.get("cvssData", {}).get("baseScore") for m in cve_item.get("metrics", {}).get("cvssMetricV40", [])), "N/A"),
"cvss_v31": next((m.get("cvssData", {}).get("baseScore") for m in cve_item.get("metrics", {}).get("cvssMetricV31", [])), "N/A"),
"cvss_v2": next((m.get("cvssData", {}).get("baseScore") for m in cve_item.get("metrics", {}).get("cvssMetricV2", [])), "N/A"),
"references": [ref.get("url") for ref in cve_item.get("references", [])]
}
def build_prompt(advisories, cve_info, refinement_feedback=None, previous_response=None):
base = f"""
You are a cybersecurity expert. Analyze the following vulnerability advisories and provide structured responses.
Ensure your response is detailed, well-structured, and follows the format below.
### CVE ID:
{cve_info['id']}
### Vulnerability Type:
### Vulnerability Description:
### Severity Level:
### Affected Versions:
### Exploitability:
### Affected Components:
### Mitigation or Workaround:
**Advisories:** {advisories}
"""
if previous_response:
base += f"\n\n### Previous Response:\n{previous_response}\n"
if refinement_feedback:
base += f"\n\n### Refinement Instructions:\n{refinement_feedback}\n"
return base
def validate_response(response):
required_sections = ["Vulnerability Type", "Vulnerability Description", "Severity Level", "Exploitability"]
for section in required_sections:
if f"### {section}:" not in response:
return False
return True
def is_significant_change(old_response, new_response, threshold=0.1):
old_len, new_len = len(old_response), len(new_response)
if old_len == 0:
return True
return abs(new_len - old_len) / old_len > threshold
def refine_deepseek_response(original_prompt, deepseek_response):
issues = []
if "Vulnerability Type:" not in deepseek_response:
issues.append("Missing 'Vulnerability Type'.")
if "Vulnerability Description:" not in deepseek_response or len(deepseek_response.split("Vulnerability Description:")[1].strip()) < 50:
issues.append("Description too short.")
if issues:
feedback = "Improve based on: " + ", ".join(issues)
return build_prompt(original_prompt, None, refinement_feedback=feedback, previous_response=deepseek_response), True
return deepseek_response, False
async def process_advisories_in_batches(results, batch_size=2):
async with aiohttp.ClientSession() as session:
for i in range(0, len(results), batch_size):
batch = results[i:i + batch_size]
advisories = "\n\n".join([f"ID: {res['ID']}\nOutput: {res['Output']}" for res in batch])
tasks = [fetch_cve_data(session, f"https://services.nvd.nist.gov/rest/json/cves/2.0?cveId={res['ID']}") for res in batch]
responses = await asyncio.gather(*tasks)
for response, res in zip(responses, batch):
if response:
cve_info = parse_cve_data(response)
prompt = build_prompt(advisories, cve_info)
retries = 3
previous_response = ""
while retries > 0:
analysis_result = chat_with_model(prompt)
if "choices" in analysis_result:
raw_message = analysis_result['choices'][0]['message']['content']
cleaned_message = clean_deepseek_response(raw_message)
if validate_response(cleaned_message):
if retries < 3 and not is_significant_change(previous_response, cleaned_message):
break
print("\nDeepSeek Analysis Result:\n", cleaned_message)
break
previous_response = cleaned_message
prompt, needs_refinement = refine_deepseek_response(prompt, cleaned_message)
if not needs_refinement:
break
retries -= 1
if results:
asyncio.run(process_advisories_in_batches(results, batch_size=2))
The refinement helper passes None as cve_info in one branch. Fix that by keeping a real cve_info dict when rebuilding prompts so cve_info['id'] never crashes. The async fetch_cve_data helper is also a sketch: prefer a single ClientSession, TLS verification aligned with your policy, and structured error handling for production.
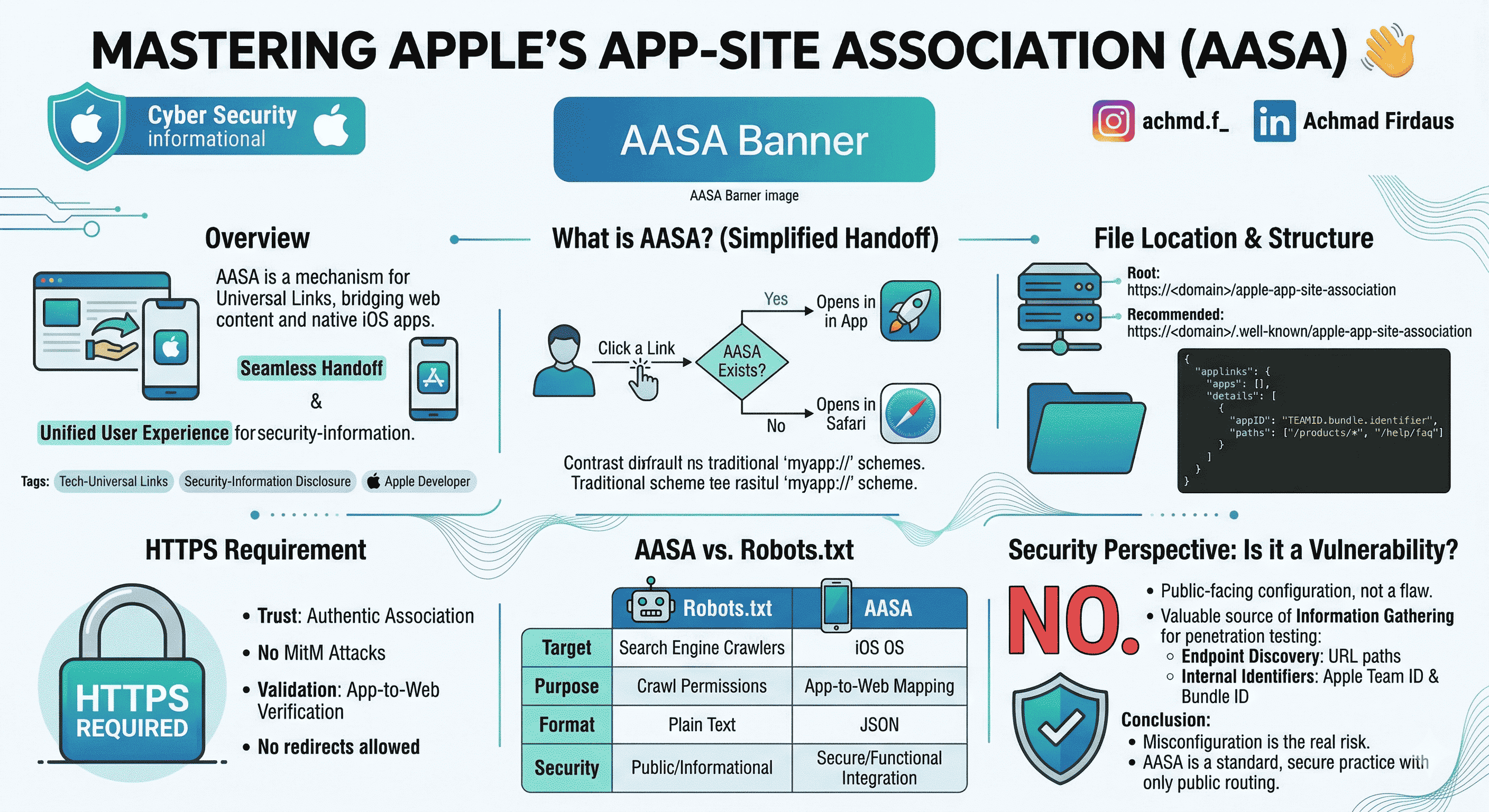
How Apple’s AASA file powers Universal Links: where to host the JSON, why HTTPS is non‑negotiable, and how to read it from a security angle, without the myths.
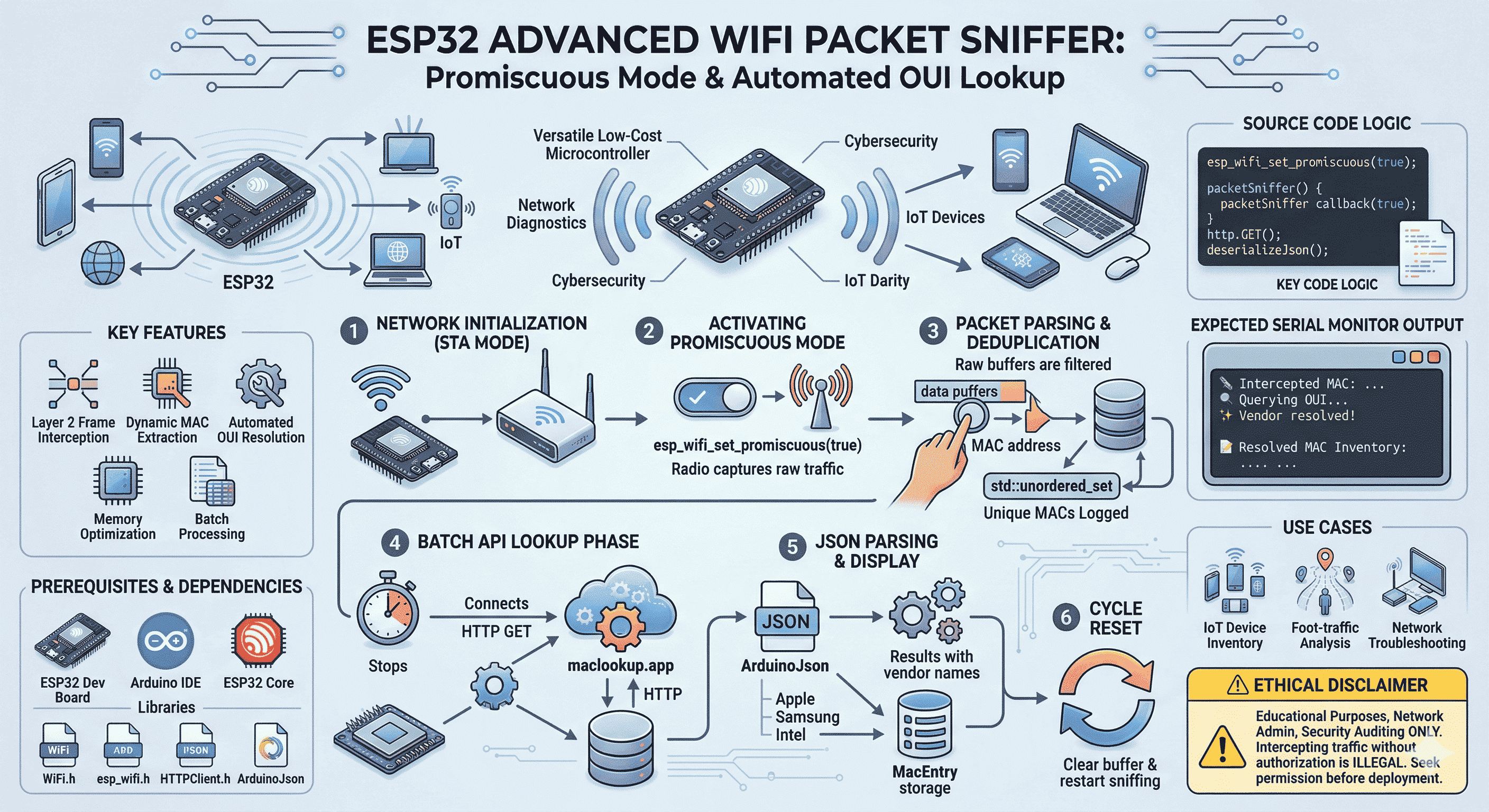
Turn an ESP32 into a Layer‑2 Wi‑Fi sniffer: capture MACs in promiscuous mode, dedupe with a hash set, then resolve vendors via a MAC/OUI API (ethics included).
Keyword + FAISS semantic search over CVE text, NVD enrichment, and structured DeepSeek analysis, with validation loops. Full architecture, stack, workflow, and source appendices.